Bueno, pues quedamos el otro día en ver cómo se hacen los
pedigríes del caso de la mujer mantiene
relaciones sexuales con dos hermanos, queda embarazada y quiere saber cuál de
los dos es el padre del bebé antes de su nacimiento.
Como ya sabéis, lo primero que tenemos que hacer es listar
los individuos necesarios para definir el pedigrí. En este caso necesitaremos
al hijo, los dos presuntos padres, la madre y claro, también necesitaremos a
los padres de los presuntos padres para poder definir que son hermanos entre
sí. Vamos a darles los siguientes nombres: Child (hijo), Thore (PP1), Daniel
(PP2), Mother (la madre, he tenido grandes tentaciones de darle un nombre de
chica GHEP o llamarla Guro, pero no liemos las cosas…J)), A (padre de Thore y
Daniel) y B (madre de Thore y Daniel).
Por tanto, el vector id sería:
c
(«Child», «Thore», «Daniel», «Mother»,
«A», «B»)
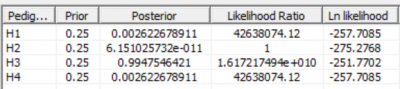
Las hipótesis de nuestro caso son: Thore es el padre vs. Daniel
es el padre, así que los vectores dadid y momid serían, para cada caso:
Ped1: Thore es el padre:
c(«Thore»,»A»,»A»,NA,NA,NA)
c(«Mother»,»B»,»B»,
NA, NA, NA)
Si leéis en vertical los tres vectores definidos hasta
ahora, estamos diciendo que Thore y Mother son los padres de Child, y que A y B
son los padres de Thore y de Daniel.
Ped2: Daniel es el padre:
c(«Daniel»,»A»,»A»,NA,NA,NA)
c(«Mother»,»B»,»B»,
NA, NA, NA)
que significa que Daniel y Mother son los padres de Child, y
que A y B son los padres de Thore y de Daniel.
Y finalmente, el vector sex, que es igual en ambos
pedigríes, claro está:
c(«male»,
«male»,
«male»,»female»,»male»,»female»)
Vale, ya lo tenemos, ahora sólo tenemos que poner todo en
orden y llamar a la función FamiliasPedigree. Quedaría así:
ped1 <-
FamiliasPedigree(c(«Child»,»Thore»,»Daniel»,»Mother»,»A»,»B»),
c(«Thore»,»A»,»A»,NA,NA,NA),
c(«Mother»,»B»,»B»,
NA, NA, NA),
c(«male»,
«male»,
«male»,»female»,»male»,»female»))
ped2 <-
FamiliasPedigree(c(«Child»,»Thore»,»Daniel»,»Mother»,»A»,»B»),
c(«Daniel»,»A»,»A»,NA,NA,NA),
c(«Mother»,»B»,»B»,
NA, NA, NA),
c(«male»,
«male»,
«male»,»female»,»male»,»female»))
¿Comprobamos
si lo hemos hecho bien? Es muy fácil! Sólo tenéis que hacer lo siguiente:
– Abrir R
– Cargar la librería Familias escribiendo: library(Familias)
– Copiar el ped1 tal y como lo hemos escrito
– Ver la representación gráfica del pedigrí
simplemente escribiendo: plot(ped1)
Y lo mismo para el ped2. Qué bonito! ¿verdad?
También podéis poner nombre a los pedigríes en la
representación gráfica. Sólo tenéis que escribir en R:
par(mfcol = c(1,2))
plot(ped1); title(«Thore»)
plot(ped2); title(«Daniel»)
par(mfcol = c(1,1))
Como
vimos en la presentación en pdf del post anterior, también se pueden escribir los
pedigríes especificando los nombres de los vectores. Podéis verlo si descargáis
los archivos ped1-Thore
y ped2-Daniel.
Todo esto que os he contado, también sirve para Familias,
claro está. Por ejemplo, si habéis definido los pedigríes en Windows Familias
como en este archivo llamado trio,
podéis ir a la ventana de Pedigrees, seleccionar un pedigrí y “Plot in R”. Os
aparecerá una ventana con el código:
#Define the persons involved in the case
persons <- c(«AF», «mother», «child»)
sex <- c(«male», «female», «female»)
#Define the pedigree
ped1 <- FamiliasPedigree(id=persons,
dadid=c(NA,NA,»AF»), momid=c(NA,NA,»mother»),
sex=c(«male», «female», «female»))
Ahora ya sabéis lo que significa todo eso!
Por cierto, Thore y Daniel, qué habéis estado haciendo para
estar involucrados en este caso???
Thore dice que hay una palabra en noruego para definir la relación entre dos hombres que tienen relaciones sexuales con la misma mujer (‘Buksvogere’), y que curiosamente, la versión en femenino de esta palabra (‘Buksvigerinner’) no existe virtualmente. También dice, sonriendo, que no hay traducción al español de estas palabras, quizás porque no sean necesarias en nuestro mundo latino… Está claro que está siendo muy sarcástico… no tenemos la palabra, pero desde luego la practicamos, tanto en femenino como en masculino  !!! Yo creo que incluso habría que inventarse algunas palabras más, sólo hay que ver los casos de paternidad que tenemos en nuestros labs!!!!
!!! Yo creo que incluso habría que inventarse algunas palabras más, sólo hay que ver los casos de paternidad que tenemos en nuestros labs!!!!