Es una actualización del curso organizado por la ISFG este verano, en el Summer School (WS7 – Pedigree analysis in R). Asistí a varios de los cursos de la ISFG 2021 y tengo que deciros que este es el que más me gustó. Los teachers son los mejores, no se puede ser más didáctico! Así que es un curso que os recomiendo mucho!
Los «patosos digitales» que hemos crecido en el mundo analógico también podemos hacer el curso. Para mi fue todo un desafío y ni mucho menos domino el tema, pero me permitió ver todo lo que se puede hacer respecto a parentescos con R, gracias a los desarrollos de Magnus y Thore.
Es que no me da la vida para más! Pero hoy me vais a
permitir que haga un poco de publicidad.
Algunos ya lo sabéis, pero acabamos de publicar un libro
sobre estadística aplicada a la identificación en desastres masivos. Thore,
Daniel y Andreas me dieron la oportunidad de participar en este libro y la
verdad es que he disfrutado muchísimo escribiendo. Sobre todo, he aprendido un
montón!
Os envío el link donde podéis encontrar la información, ya
que muchos me lo habéis pedido:
En el libro podréis encontrar información muy útil sobre
muchas cuestiones: cómo examinar los datos genéticos post-mortem para su
re-asociación o establecimiento de relaciones familiares, cómo evaluar o
encontrar las mejores muestras de referencia a través de simulaciones, cómo se
puede usar la probabilidad a priori de identificación, qué tipos de búsquedas
se pueden hacer y cómo valorar sus resultados… ¡y lo que se nos viene encima!:
el uso de la genealogía forense aplicada a los casos masivos de identificación.
Pero también encontraréis varios abordajes posibles y
novedosos para resolver los casos. Para abrir boca, aquí os mando un artículo (en
español, que placer!!) que también acabamos de escribir (Yari, Elias y nuestro
querido y añorado Ángel) y que trata precisamente de las distintas maneras de enfrentarse a la tarea de identificación a
gran escala y que se describen en el libro (one to one, PM-driven, AM-driven y
el maravilloso Global approach!):
Tanto los autores del libro como los del artículo esperamos
que sean de utilidad para vosotros. Todo está hecho con mucho cariño y siempre
pensando en vosotros y en nuestra queridísima genética forense. Aunque desde
luego, estos matemáticos no nos dejan aburrirnos ni un minuto!
Tengo pendiente otro post cortito que creo que os va a ser
también de mucha utilidad porque os va a evitar trabajo. A ver si os lo mando
pronto!
Muchos abrazos para todos! Os echo muchísimo de menos!
Ya os he hablado de Magnus Vigeland
(ver https://parentela.familias.name/category/category4/). Pues bien, él ha
desarrollado mucho software en R, y ahora Familias puede aprovecharse de ese
trabajo!
Thore me ha enviado un ejemplo en
el que se demuestra claramente el potencial que tiene combinar Familias y R.
Podemos leer en R un archivo de Familias (.fam) con el comando
«readFam», y también podemos dibujar los pedigríes definidos en el
archivo de Familias con el comando «plotPedList».
Para poder hacerlo primero tenéis
que saber dónde debe estar almacenado el archivo .fam para que R lo pueda leer.
Para esto sólo tenéis que teclear en R:
getwd()
Y R os responderá dónde tenéis
que almacenar el archivo .fam (también
podríais indicar una ruta, pero es más fácil almacenar el archivo en el working
directory de R).
Bueno, pues vamos a ver el ejemplo de Thore usando el archivo de familias sibs3.fam que podéis descargar aquí (ya sabéis, teclas Ctrl + S para descargarlo) y que debéis guardar en el working directory.
Ahora tenéis que instalar el
paquete de R para aplicaciones forenses
llamado «forrel». Para
instalarlo sólo debéis teclear lo siguiente en Rstudio o en la consola R (se
necesita conexión a internet):
install.packages(«forrel»)
La
instalación de forrel sólo hay que hacerla una vez.
Ok,
ahora ya estamos preparados para el ejemplo. Debéis teclear en R:
Maravilloso!! Muy útil para
incluir los pedigríes en nuestros informes!!
También podemos calcular
directamente los LRs en R si además tecleamos:
kinshipLR(x,
ref = 3)
Y obtendremos:
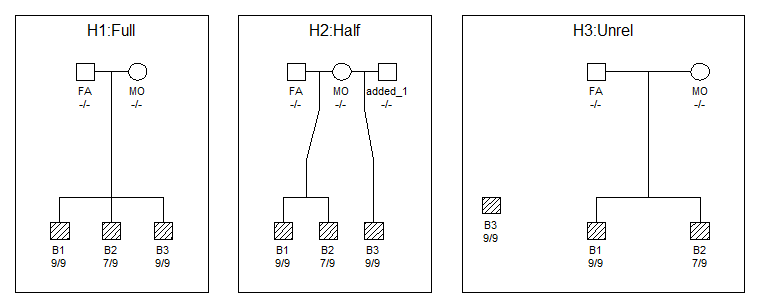
## Total LR:
## H1:Full
H2:Half H3:Unrel
## 8.333333 2.916667 1.000000
En el comando anterior, ‘ref = 3’ significa que los LRs están
escalados con respecto a H3, es decir os da el LR con ‘H3:Unrel’ como referencia. Podéis encontrar
más documentación y ejemplos si tecleáis:
?kinshipLR
Si decidís usar el working
directory, cada vez que queráis usar esta herramienta con otro archivo, solo
debéis modificar el nombre del archivo en las líneas de comandos de arriba:
En lugar de x =
readFam(«sibs3.fam», verbose = F), debeis escribir x = readFam(«nombre de vuestro archivo.fam«,
verbose = F)
O si preferís, en lugar de
guardar el archivo .fam en el working directory de R, también podríais indicar
la ruta en donde lo tengáis guardado, por ejemplo:
x =
readFam(«C:/Users/lourditasmt/Documents/sibs3.fam», verbose = F)
Magnus Dehli Vigeland y Thore Egeland van a impartir el curso «Statistical methods in relatedness and pedigree analysis» del 6-10 de enero de 2020 en Oslo (Domus Medica, Univ of Oslo). ¿Qué significa estar emparentado? ¿Hay hermanos más parecidos que otros? ¿Cómo se mide y se estiman las relaciones genéticas? Y lo más importante: ¿El Príncipe Harry está emparentado con Meghan???
Además de estos temas, se tratarán sus aplicaciones a la medicina y la genética forense, incluyendo cálculos y visualizaciones en R.
El curso está organizado por NORBIS, es abierto para todos, es gratuíto y no se necesitan conocimientos previos para participar (pero se necesita un ordenador con R instalado)
Podéis encontrar información adicional y cómo registraros aquí:
Como sabéis, se trata de una guía muy divulgativa enfocada a que los jueces, fiscales y abogados tengan una visión real de lo que puede ofrecer el análisis de ADN con fines forenses. Pero nos parece que también puede ser válida para estudiantes y personas que están interesadas en el tema.
Quiero agradecer a nuestros queridos Ángel Carracedo y Antonio Alonso todo su perfecto trabajo en la adaptación y presentación de esta guía. Peter Schneider también estuvo muy pendiente de que este proyecto saliera adelante. Gracias a nuestra prestigiosa sociedad, ISFG, la versión española es hoy una realidad pues ha financiado su edición.
Hace un par de semanas tuve la oportunidad de viajar a México a dar un curso con Thore sobre Familias. Esta vez hasta tuvimos tiempo de pasear un poco por las pirámides, ir a la Plaza Garibaldi a escuchar unos mariachis y disfrutar de las cervezas micheladas. Pero no os escribo para daros envidia… sino para poneros el link del curso en el que podréis descargar las charlas, por si estuvierais interesados: http://www.familias.name/Courses.html
Esta vez hemos dedicado bastante tiempo al módulo DVI de Familias. Tiene herramientas muy útiles, algunas de las cuales ya hemos visto en este blog, como las simulaciones (http://parentela.familias.name/#category4). Pero además podréis ver cómo hacer la re-asociación de muestras Post-Mortem, chequear si los pedigríes tienen inconsistencias, dibujar los pedigríes… en fin, esperamos que os sea muy útil!!
Olga Barragán, del Comité Internacional de la Cruz Roja, fue quien organizó el curso, con su fantástico equipo. Y también nos paseó! La gente en México, encantadora, como siempre!! Que viva a México!!
Un post corto para informaros de que justo esta semana en España hemos sacado un documento sobre recomendaciones para el uso forense del ADN. Son sólo cuatro páginas de recomendaciones que creemos necesarias. Estamos difundiendo estas recomendaciones a jueces, fiscales, abogados, legisladores, genetistas, policía y a cualquier persona que pueda estar interesada en el tema. No sé si os puede ser útil para algo, pero por si acaso, aquí os pongo el link del lanzamiento. Podéis descargar el documento desde ahí: https://www.fidefundacion.es/GT-ADN-el-valor-de-las-pruebas-forenses-y-de-los-limites-de-su-uso_a815.html
Las Fundaciones Fide y Garrigues nos han ayudado con la difusión. Muchos abrazos para tod@s!!
Para retomar la actividad después de las vacaciones y unos
cuantos viajes hoy os propongo echar un vistazo a un par de noticias que para
mí han sido impactantes.
La
primera de ellas tiene que ver con la localización de un cadáver en Chipre. Como
muchos sabéis, a mediados del siglo XX (1963-1964 y 1974) se generó un
conflicto allí entre turco-chipriotas y greco-chipriotas. Como resultado el
país ha quedado dividido en dos partes y es bastante impactante atravesar el
único muro que queda dentro de Europa y que separa la República Turco-chipriota
(no reconocida como país, excepto por Turquía) y la greco-chipriota. Pues bien,
el Programa de Naciones Unidas para el Desarrollo (UNDP) está colaborando en la
identificación de las 2003 víctimas del conflicto (http://www.cmp-cyprus.org/).
Y hemos tenido el honor de que la coordinadora forense de tal proyecto de
identificación fuera nuestra querida Yarimar Ruiz, una genetista buenísima que
se formó en el Laboratorio de Ángel Carracedo (cómo no!!).
Bueno, a lo que iba, que me despisto. Recientemente se ha
localizado uno de los cadáveres gracias a que un científico localizó una
higuera en una zona donde no era habitual ver este tipo de árbol. Al extrañarse
por este hallazgo, el científico se acercó al árbol y empezó a inspeccionar su
raíz, encontrando una serie de restos humanos. Los restos han sido
identificados como pertenecientes a una de las víctimas del conflicto, y se
cree que esta persona se alimentó con un higo antes de morir. La semilla del
higo germinó, y creció el árbol!! Os podéis imaginar el significado sentimental
que tendrá ese árbol para sus familiares. Alucinante!! Podéis encontrar el
recorte de prensa aquí:
La segunda
de ellas seguro que muchos de vosotros la conocéis, es el caso del asesino del
Golden State (https://www.univision.com/los-angeles/kmex/noticias/asesinatos/un-sitio-web-genealogico-llevo-a-los-investigadores-hasta-el-asesino-del-golden-state).
Se trata de la detención de Joseph James DeAngelo Jr., de 72 años, sospechoso
de haber cometido varios homicidios y numerosas agresiones sexuales en varias
ciudades de California durante los años 70 y 80. La policía utilizó los
servicios de una compañía on-line que ofrece servicios de genealogía. Se
analizó una de las muestras recolectadas en una de las escenas del delito
(700.000 SNPs). Las propias compañías ofrecen candidatos de quienes pueden ser
tus posibles familiares, de entre los clientes que tienen. Y tras varios
candidatos, eureka! uno de Sacramento, una de las ciudades donde se cometieron
algunos crímenes. Lo demás ya es fácil, una vez tienes a un candidato, sólo
tienes que tomar muestras abandonadas por los familiares de ese candidato y ver
cuál de ellas coincide con el perfil genético anónimo tradicional (nuestros
adorados STRs) detectado en varias escenas. Pero lo más sorprendente de este
caso es que el candidato era un primo tercero de Joseph James DeAngelo Jr.,
según me comentó Thore, quien hizo una búsqueda intensa para obtener
información fiable sobre el caso (Ehrlich et al 2018: https://www.biorxiv.org/content/early/2018/06/19/350231).
La última semana de agosto tuve la oportunidad de asistir a
un fantástico meeting de matemáticos en Colonia (Alemania) y Thore presentó el
caso allí. Thore coméntanos, ¿tú crees que la policía tuvo mucha suerte en este
caso?
Y seguro que en la mente de muchos queda esta pregunta: ¿es
ético utilizar la información de familiares generada con fines distintos a los
de una investigación criminal? ¿Podemos evitar que se utilice esta nueva
herramienta? Pues me temo que el caso de DeAngelo no es el único… el asesinato
de KRISTY MIRACK también tiene un sospechoso encontrado a través de un familiar
que se realizó una prueba de ADN en una de estas compañías (https://www.debate.com.mx/mundo/crimen-asesinato-maestra-christy-mirack-dj-freez-sospechoso-muerte-20180626-0088.html).