Bueno, pues veamos ahora cómo se calcula una probabilidad a
posteriori en forma de apuesta (Bayes Theorem in odds form). Nos basaremos en
la diapositiva 30 de la charla de Thore, y usaremos el mismo ejemplo que
veníamos usando.
Posterior
odds de la comparación de H3 (gemelos) y H1 (hermanos):


Es decir, H3 (gemelos) es 2000 veces más probable que H1
(hermanos) teniendo en cuenta estos priors.
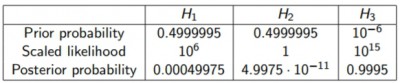
No sabemos si hay más hipótesis o no, si sólo hubiera una más (por ejemplo H2 =
no relacionados), su prior sería = 1 –
P(H1)-P(H3)=0.4999995. Pero podría haber más hipótesis, y el prior 0.4999995 de H2 se subdividiría entre
las hipótesis adicionales. En cualquier caso, el cálculo y la interpretación que
hemos realizado en forma de odds sería igual de válido, ya que sólo estamos
comparando H3 y H1.
Veis entonces que los posterior
en forma de odds nada tienen que ver con las probabilidades a posteriori (que deben tener en cuenta
todas las posibilidades y sumar 1!!).
Quería también poneros un ejemplo clarísimo en el que
enseguida nos damos cuenta de que no conocemos todas las hipótesis posibles. Imaginaros
que nos piden saber si un varón y una mujer son hermanos en un caso de
inmigración, y que resulta que al analizar ADNmt nos damos cuenta de que no
pueden ser hermanos de madre porque sus haplotipos son distintos. Claramente,
no conocemos todas las hipótesis: podrían ser medio-hermanos, primos, no estar
relacionados…Le pregunté a Thore sobre esto y me ha recomendado leer este
paper:
Karlsson et
al., 2007. DNA testing for immigration cases: the risk of erroneous
conclusions. For. Sci. Int. 172: 144-149
Bueno, seguro que os resulta interesante a los que hacéis
casos de inmigración ilegal y reagrupación familiar. Ya me diréis que os
parece!!
***Comentario de revista Hola: el primer autor de este
paper (Andreas Karlsson) es en realidad nuestro conocidísimo Andreas Tillmar,
que se puso el apellido de su mujer cuando se casó. Yo creo que este cambio de
Karlsson a Tillmar puede deberse a dos motivos: quizás lo hizo porque Karlsson
es el tercer apellido más frecuente en Suecia, o quizás porque está enamoradísimo
de su esposa. La segunda opción es tan bonita….